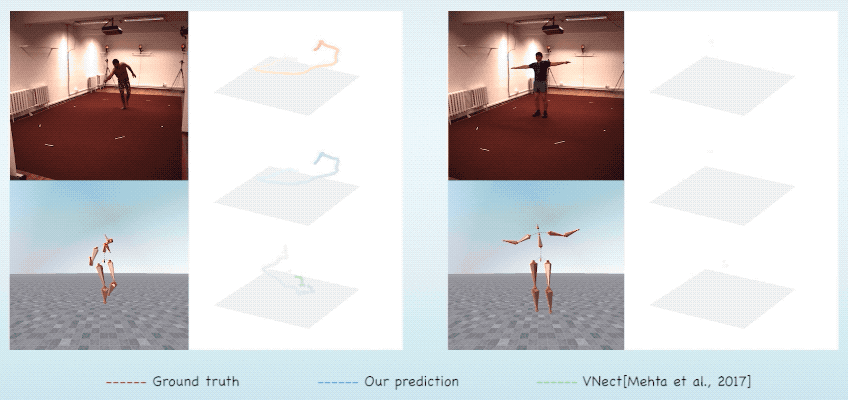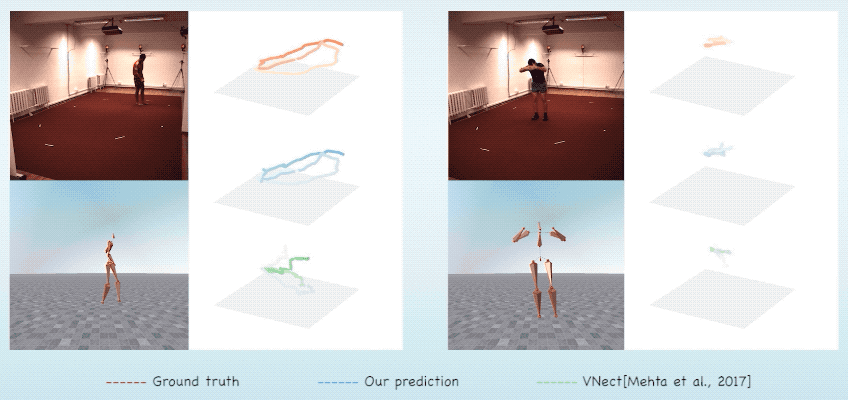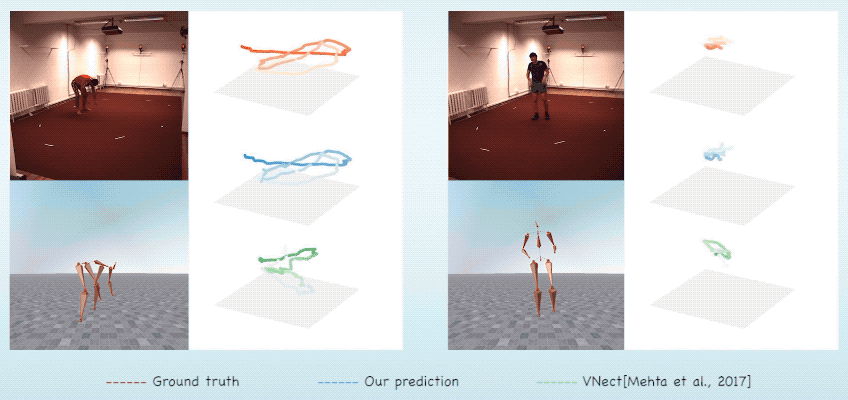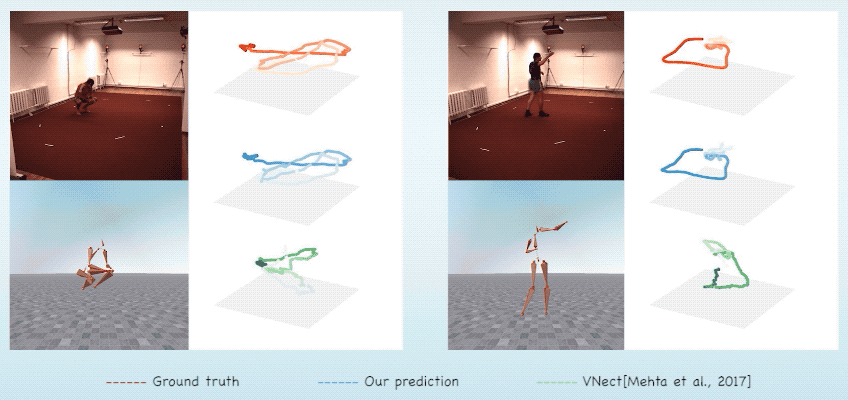
Abstract & Method
We introduce MotioNet, a deep neural network that directly reconstructs the
motion of a 3D human skeleton from monocular video. While previous methods rely on either rigging or inverse
kinematics (IK) to associate a consistent skeleton with temporally coherent joint rotations, our method is the
first data-driven approach that directly outputs a kinematic skeleton, which is a complete, commonly used,
motion representation. At the crux of our approach lies a deep neural network with embedded kinematic priors,
which decomposes sequences of 2D joint positions into two separate attributes: a single, symmetric, skeleton,
encoded by bone lengths, and a sequence of 3D joint rotations associated with global root positions and foot
contact labels.
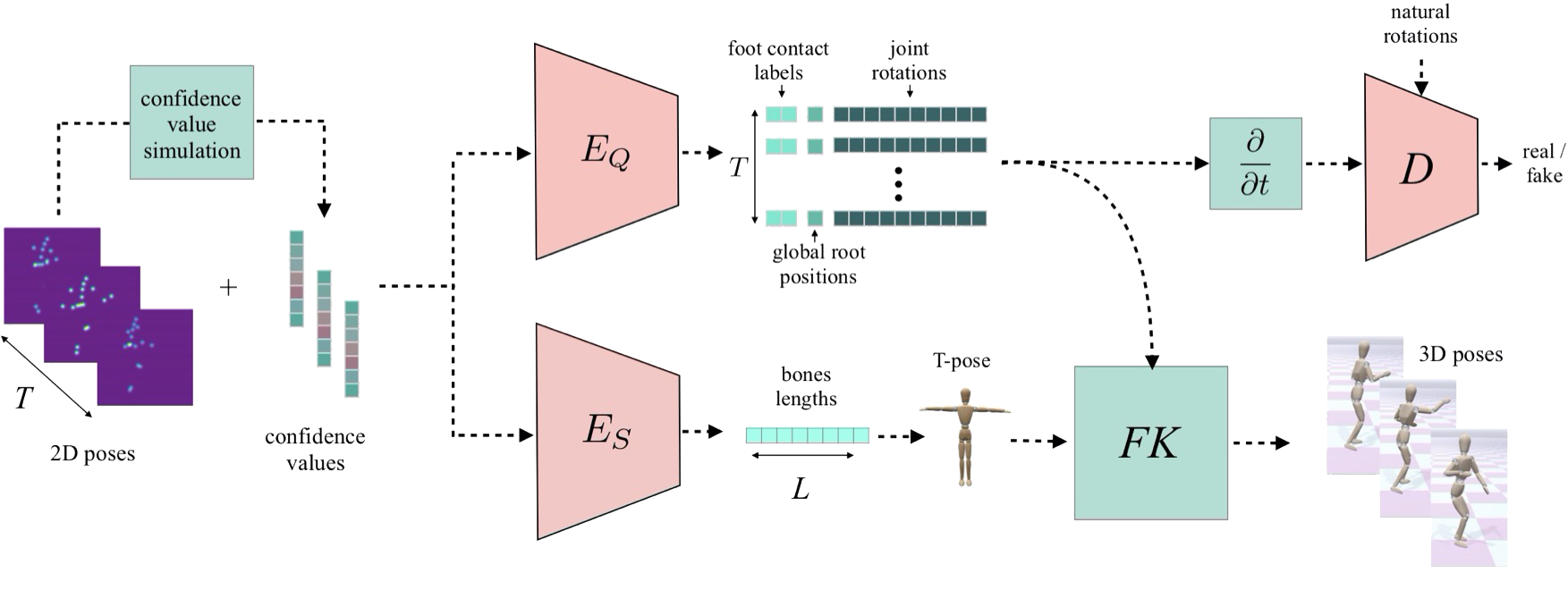
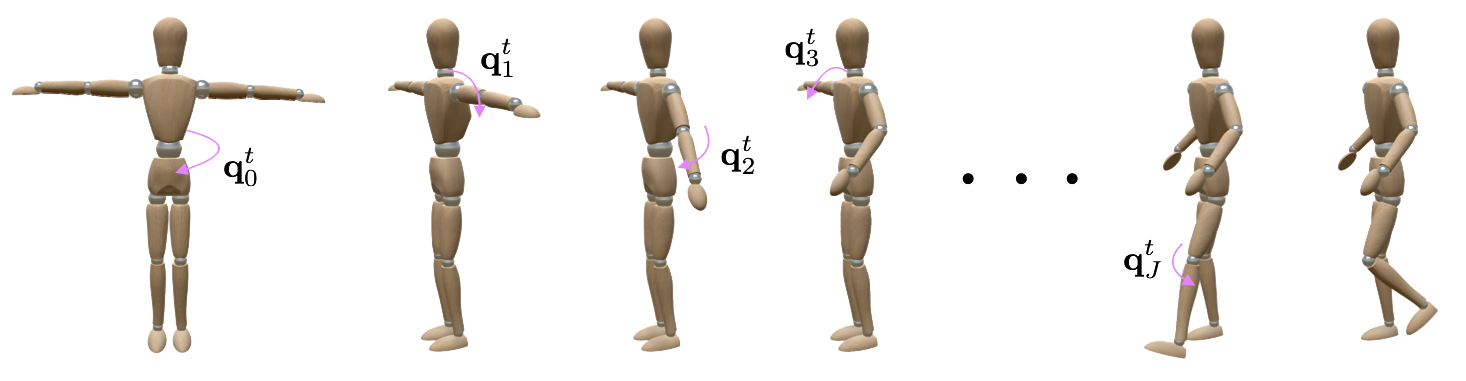
These attributes are fed into an integrated forward kinematics (FK) layer that
outputs 3D positions, which are compared to a ground truth.
The key advantage of our approach is that it learns to infer natural joint
rotations directly from the training data, rather than assuming an underlying model, or inferring them from
joint positions using a data-agnostic IK solver.